パートナー募集ページ
トピックス
事業内容
事業内容
コンサルティングビジネス
ソリューションビジネス
システムインテグレーションビジネス
デジタルトランス
フォーメーションビジネス
フォーメーションビジネス
取扱製品・サービス
事例紹介
セミナー・イベント情報
企業情報
企業情報
経営理念
企業戦略
事業内容
会社概要
役員体制
アクセス
採用情報
企業戦略
お問い合わせ
お問合せ
メニュー
事業内容
コンサルティングビジネス
ソリューションビジネス
システムインテグレーションビジネス
デジタルトランス
フォーメーションビジネス
アウトソーシングビジネス
企業情報
経営理念
企業戦略
事業内容
会社概要
役員体制
アクセス
About
最適なビジネスパートナーとして
積み上げた信頼
1985年の創業以来、
お客様に夢と未来を提供することをコンセプトに
ソフトウエア開発、製品導入サポートなど
幅広い分野でサービスを提供してまいりました。
「経営」と「情報」のプロフェッショナルとして、
これからもお客様に夢と未来を提供してまいります。
企業情報を見る
Outsourcing
Solution
Digital Transformation
System Integration
Consulting
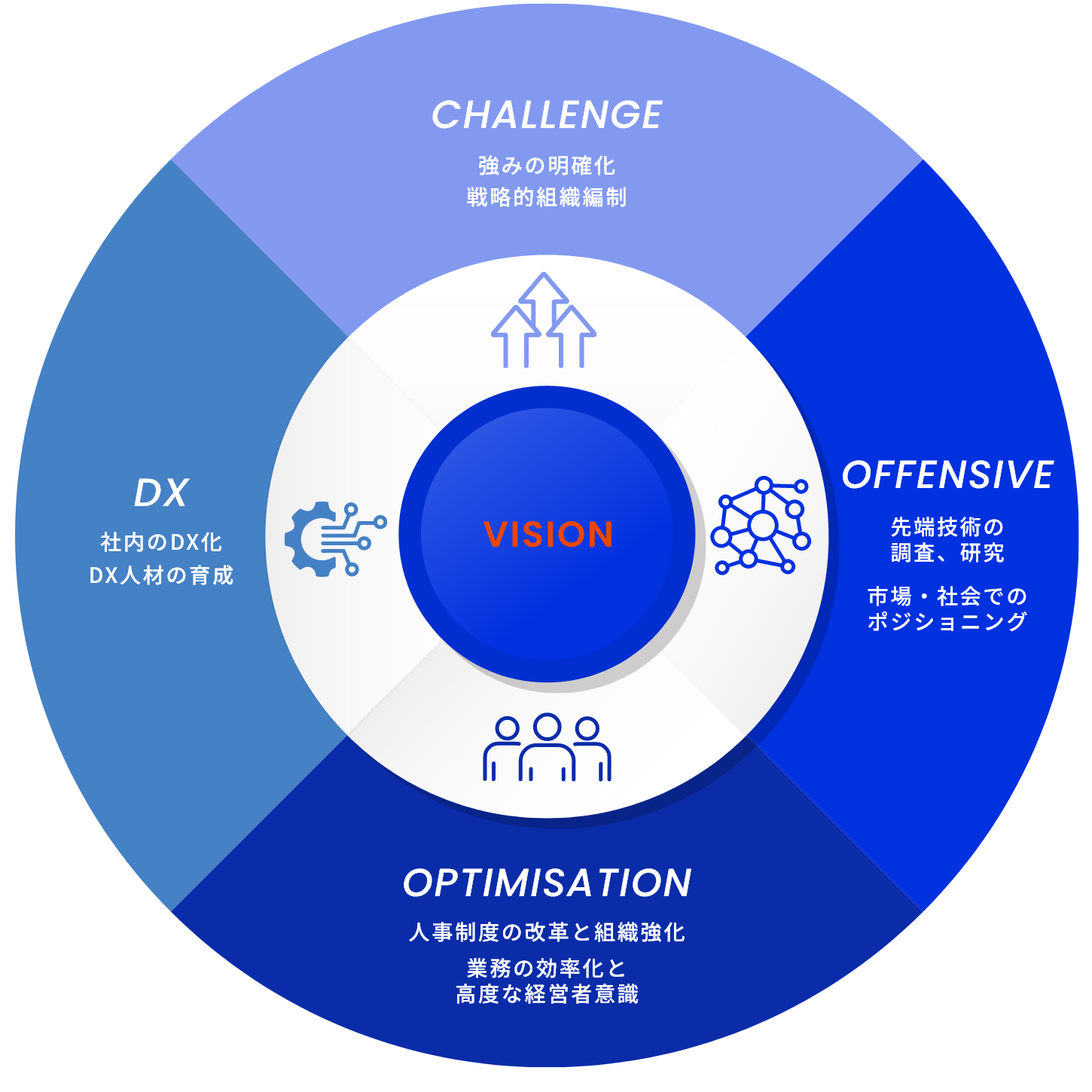
Challenge 25
2025年に向けた企業戦略
時代の変化による激しい技術革新が進む中で、常に
新技術・新分野に取り組み、お客様の課題解決の為の
ITサービスを創造していきます。
ワンストップで提供できるサービスを軸に積極的に
”攻め”の姿勢で提案をしていく企業を目指します。
企業戦略を見る
Business
事業内容
導入事例
取扱製品・サービス一覧
Consulting
コンサルティングビジネス
お客様のビジネスにあった最適な業務改善やシステムをご提案
System
Integration
システムインテグレーションビジネス
お客様の理想をカタチにするスクラッチ開発型サービス
Digital
Transformation
デジタルトランスフォーメーションビジネス
次世代のソリューションを常に研究し、新たなソリューションやサービスをご提供
Solution
ソリューションビジネス
幅広いソリューションの組み合わせで最適なサービスを実現
Outsourcing
アウトソーシングビジネス
システムの運用・保守をまるごとお任せ
導入事例
取扱製品・サービス一覧
PRODUCTS
取扱製品・サービス
取扱製品ラインナップ
日本ソフトウエアでは、豊富なITサービス、製品を扱っております。
コンサルティングから導入サポート、独自システムの開発まで幅広く対応します。
取扱商品・サービス
TOPICS
お知らせ
2024.04.18
NEW
ニュースレター
TALON関連サービスメニューのご紹介
2024.02.29
ニュースレター
システム運用保守 プレアセスメントのご紹介
2024.01.04
ニュースレター
新年のご挨拶
2023.11.15
ニュースレター
ZAC×NSKが生み出す相乗効果について
一覧へ
ITと人をつなぐ挑戦
NSK 採用サイト
recruit
CONTACT
お問い合わせ
お見積り依頼・資料請求等、お気軽にお問い合わせください。
フォームでのお問い合わせ
お問い合わせ
お電話でのお問い合わせ
03-5833-7631
ビジネスパートナー募集
サイトマップ
品質方針
情報セキュリティ基本方針
個人情報保護方針
個人情報の取扱について
記載されている会社名、製品名とサービス名の一部は、日本ソフトウエア株式会社、または各社の商標もしくは登録商標になります。